Login / Register
Next-gen AI storage: Micron® SSDs, WEKA™, AMD EPYC™ and Supermicro
For Supercomputing 2022, the Micron® Data Center Workload Engineering team, WEKA, AMD and Supermicro joined forces to be the first to test 4th Gen AMD EPYC platforms in a WEKA distributed storage solution for AI workloads.
We deployed a solution that took advantage of the best in bleeding-edge hardware and software and used a new benchmark from the MLPerf™ storage working group to measure its ability to support demanding AI workloads.
When I first posted about this work on LinkedIn, I learned that this group was the first to test MLPerf storage at scale and the first to test WEKA on AMD Genoa processors. Liran Zvibel (co-founder and CTO at WEKA) commented that he was pleased this process had gone so smoothly and that there is often some difficulty “running for a first time on a completely new platform (new PCIe® bus, new CPU, etc).”
WEKA version 4 expands its software-defined storage stack to increase scalability and performance per node, necessary for taking advantage of next-gen systems. According to WEKA, it also:
Is a data platform designed for NVMeTM and modern networks.
Improves performance for bandwidth and IOPs, with reduced latency, and metadata.
Supports broad, multiprotocol access to data on-premises or in the cloud.
Is faster than local disks for mixed workloads and small files without requiring tuning.
Supermicro provided six of its new AS-1115CS-TNR systems to use for WEKA cluster nodes. These platforms take advantage of 4th Gen AMD EPYC CPUs along with a PCIe® Gen5 backplane. The specifics of the systems under test are:
AMD 4th Gen EPYC 9654P CPU (96-core)
12x Micron DDR5 4800MT/s RDIMMs
2x NVIDIA® Connectx®-6 200Gbe NICs
We deployed this solution taking advantage of Micron DDR5 DRAM, which provides increased performance and throughput and faster transfer speeds than previous-gen DDR4.
We also used the Micron 7450 NVMe SSD — built with Micron 176-layer with CMOS under the Array (CuA). It combines high performance with excellent quality of service, providing superior application performance and response times.
For networking, we used NVIDIA ConnectX-6 200Gbe NICs with 2 NICs per storage node and 1 NIC per client. We recommend using the PCIe Gen5 400Gbe NVIDIA ConnectX-7 NIC when it becomes available to simplify the network configuration and deployment with similar performance.

Baseline Results
We tested FIO performance across the 12 load generating clients to measure maximum system throughput, scaling from 1 to 32 queue depth (QD) per client across all clients.
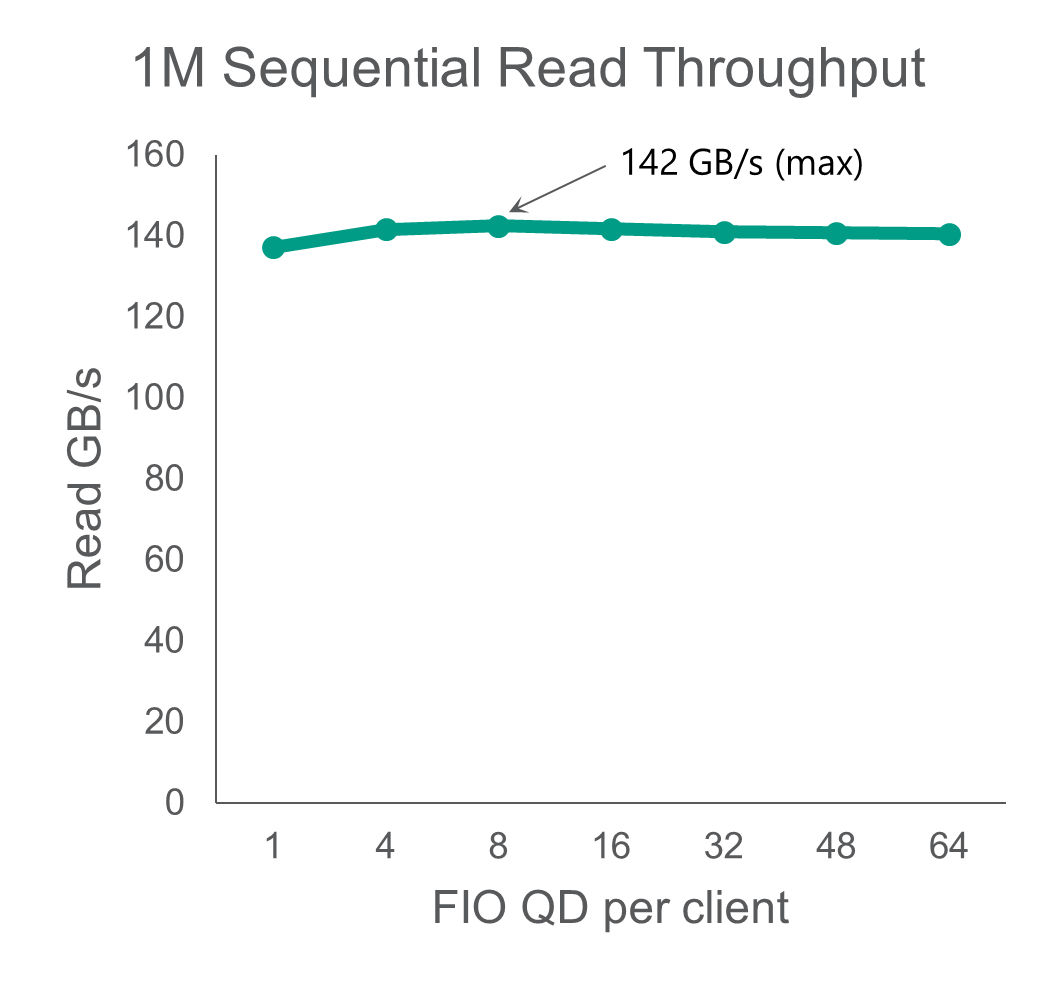
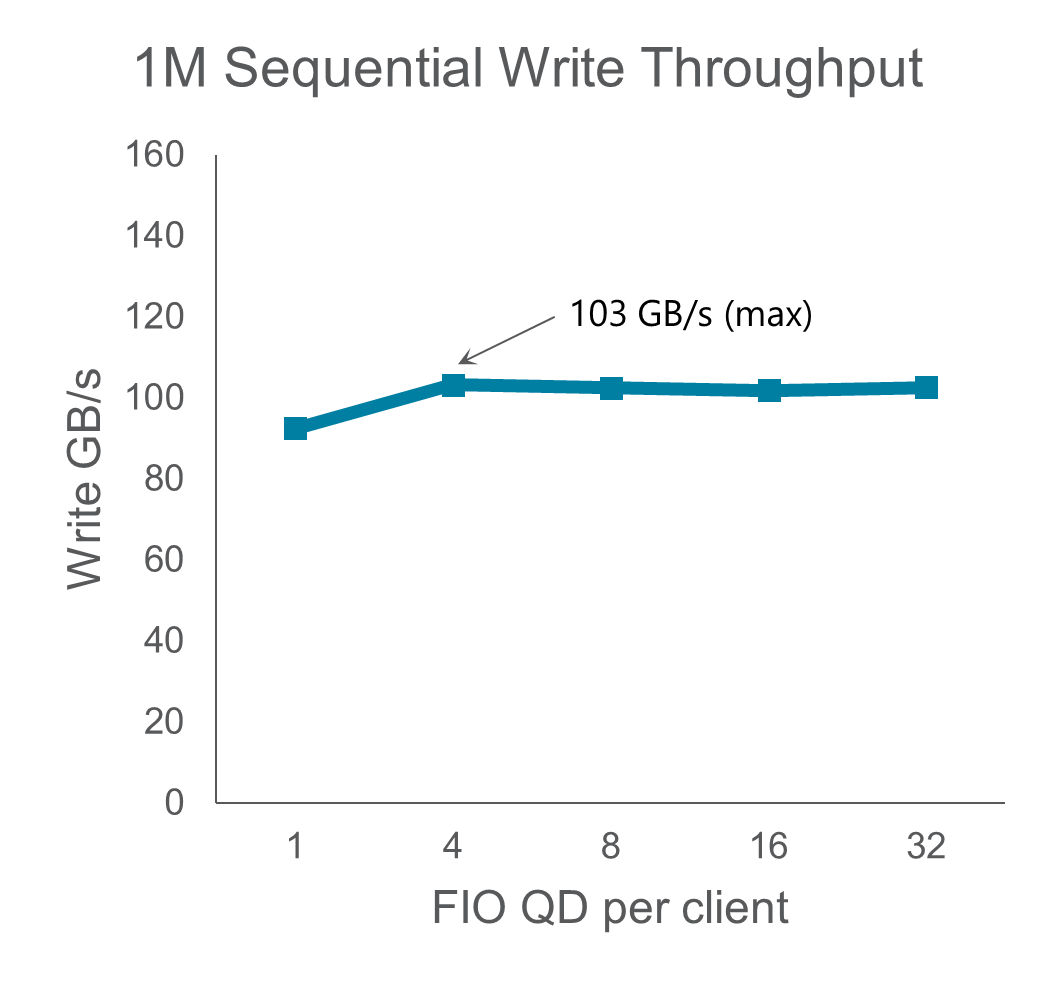
We reached 142 GB/s for 1MB reads and 103 GB/s for 1MB writes. The write throughput is staggering when accounting for the erasure coding 4+2 scheme that WEKA uses. This is enabled by extremely high compute performance from the 4th Gen AMD EPYC CPU and the increased performance of Micron DDR5 DRAM.
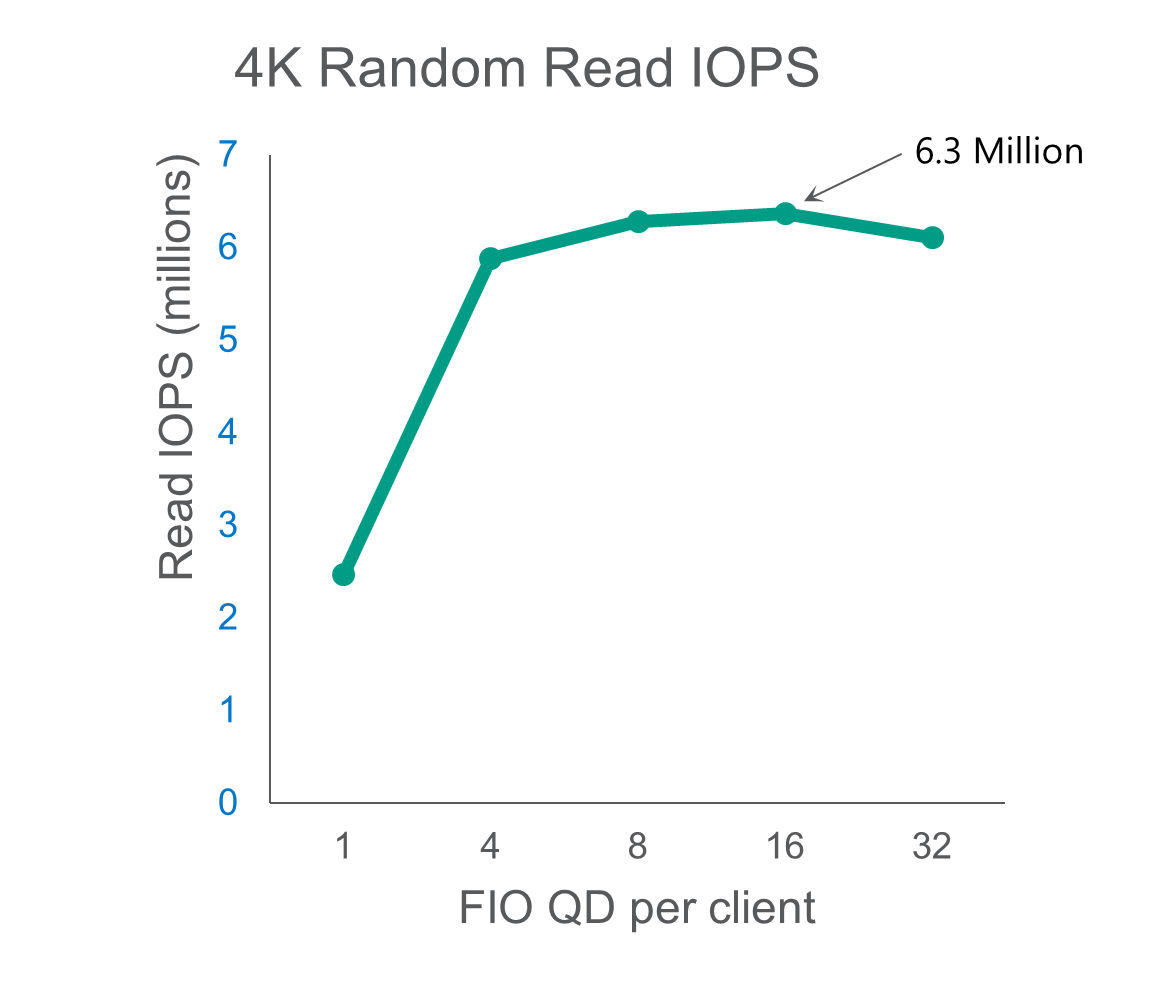
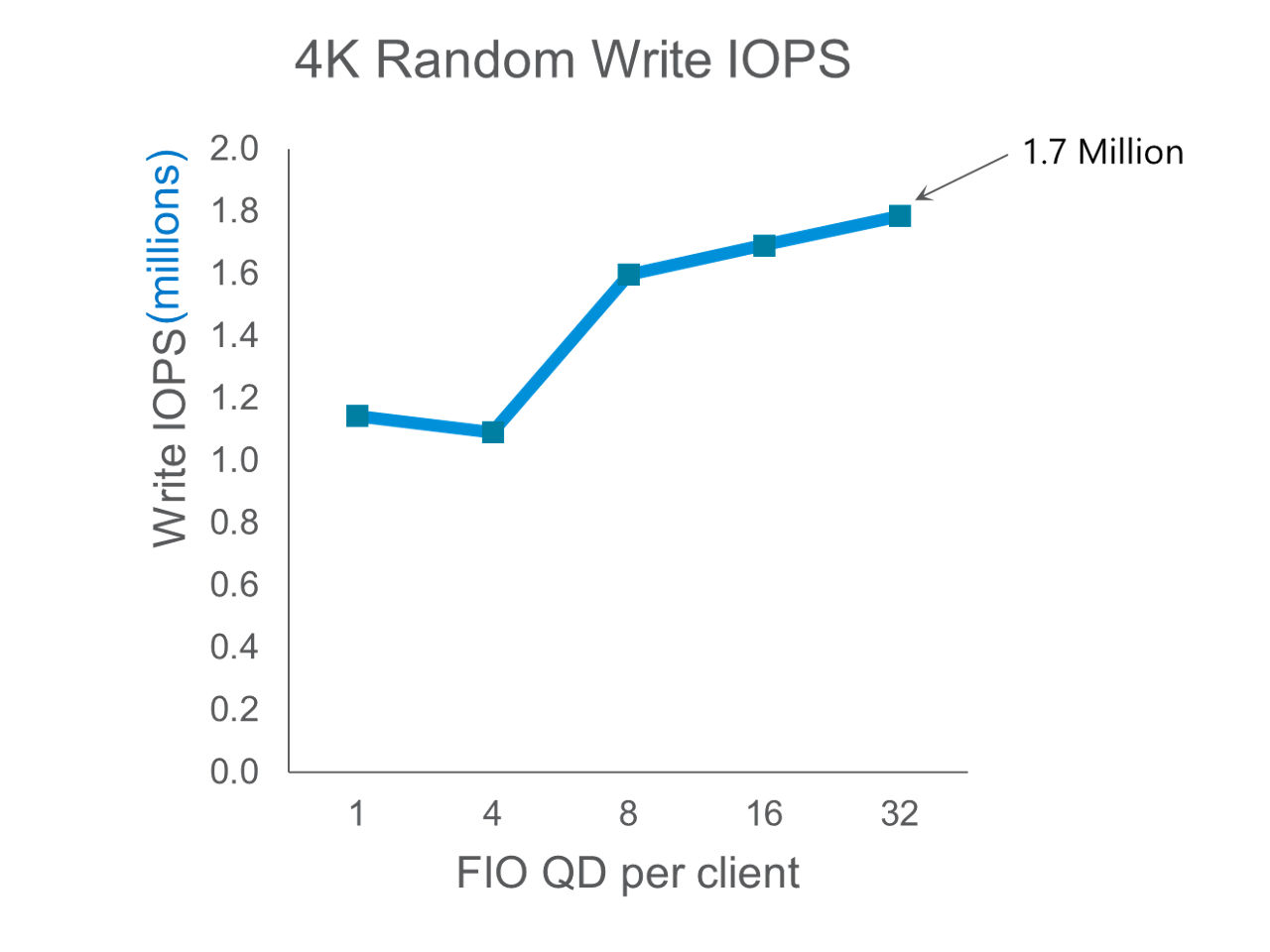
On random workloads, we measured 6.3 million 4KB read IOPS and 1.7 million 4KB random write IOPS. These reflect excellent small block random performance from the cluster, which is enabled by the performance and latency of the Micron 7450 NVMe SSD along with WEKA’s focus on better than local small block NVMe performance.
AI/ML Workloads: MLPerf Storage
The MLPerf storage benchmark is designed to test realistic storage performance for AI training for multiple models. It uses a measured sleep time to simulate the time it takes for a GPU to request data, process it, and then ask for the next batch of data. These steps create an extremely bursty workload where storage will hit its maximum throughput for short periods of time followed by sleep. There are some major advantages to this AI benchmark:
- Is focused on storage impact in AI/ML
- Has realistic storage and pre-processing settings
- Requires no GPU accelerators to run
- Can generate a large data set per model from seed data
We tested with the following settings:
- MLPerf Storage v0.4 (preview)
- Workload: Medical Imaging Segmentation Training
- Model: Unet3D
- Seed Data: KiTS19 set of images
- Generated Dataset size: 2TB (500GB x 4)
- Framework: PyTorch
- Simulated GPU: NVIDIA A100
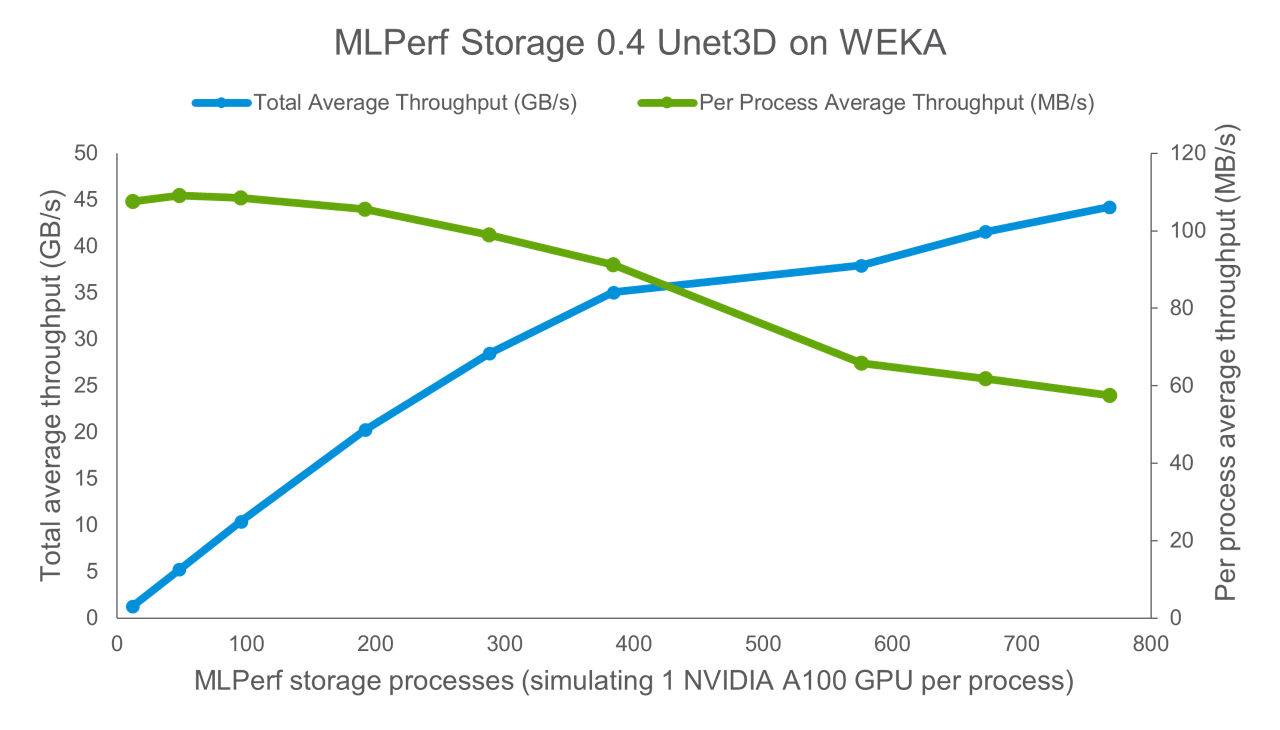
One important aspect of this benchmark is that each MLPerf Process represents a single GPU running the AI training process. Scaling up MLPerf storage processes reaches a maximum throughput of 45 GB/s; however, the per process performance begins to decrease at around 288 processes. That data point represents 288 NVIDIA A100 GPUs running Unet3D Medical Image Segmentation training processes simultaneously, or the equivalent of 36 NVIDIA DGX A100 systems!
Would you like to know more?
Be sure to check out the following resources, too:
